Illustration
Når en computer skal læse og danne mening ud fra tekst, fx ved klassificering af patientjournaler, kræver det at hvert ord omdannes til en række af tal. Transformationen hvor ord omdannes til tal er meget vigtig, da det danner rammen for computerens forståelse af hvert ord, som efterfølgende kan bruges til at opnå forståelse af hele sætninger eller dokumenter. Hvert ord repræsenteres typisk af 100-300 tal, og denne række af tal kaldes en word embedding.
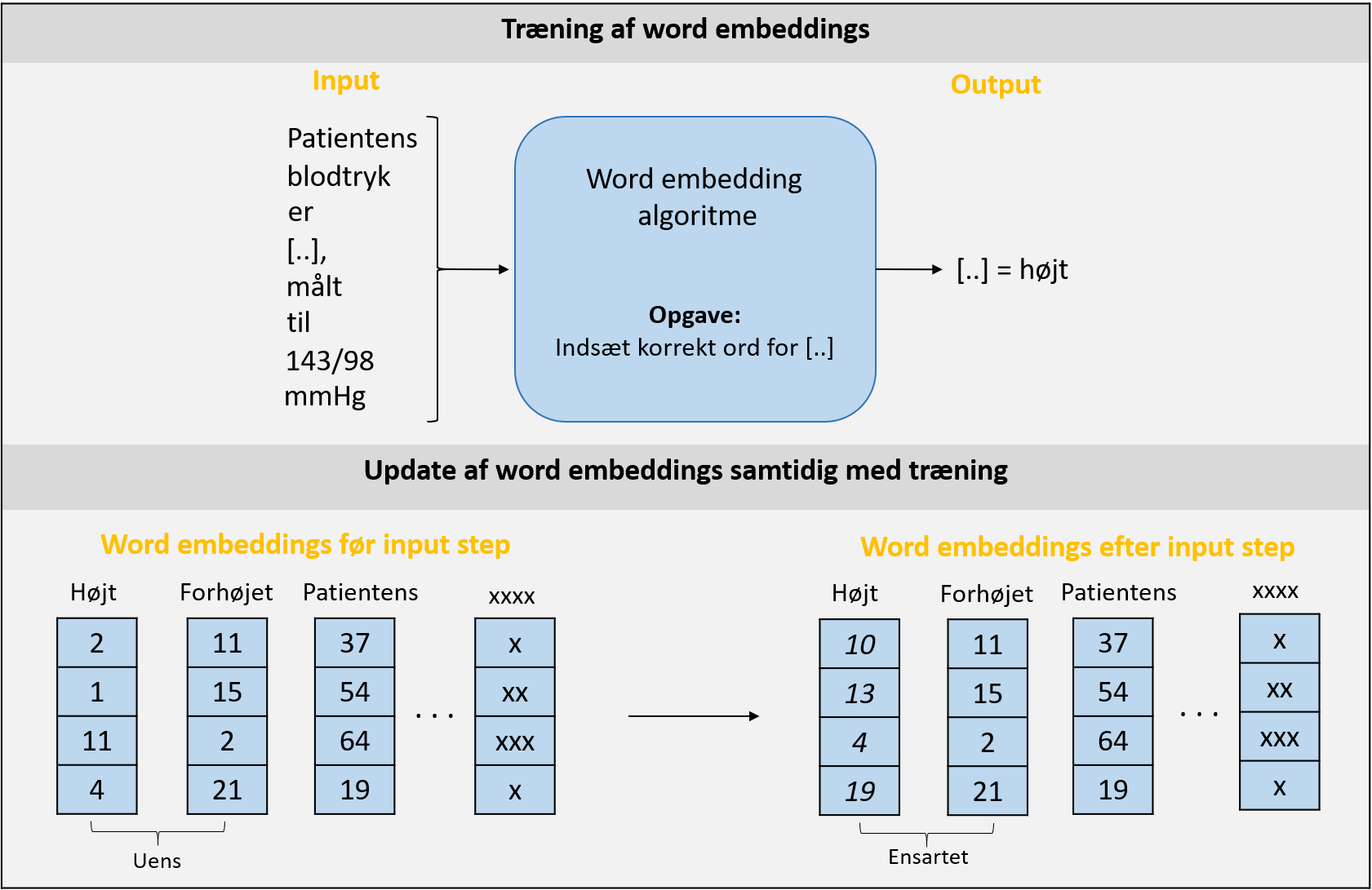
Word embeddings kan bl.a. udvikles ud fra teorien om, at meningen af et ord dannes ud fra dens kontekst, og derfor vil ord der minder om hinanden ofte stå i samme kontekst. Ved at træne et lille kunstigt neuralt netværk der skal indsætte det korrekte center ord i en sætning, begynder computeren at få en forståelse af ordenes betydning, hvilket indkodes i ordets word embedding.
I praksis kan computeren fx få til opgave at indsætte det korrekte ord i sætningen ’’Patientens blodtryk er [..], målt til 145/92 mmHg’’. Hvis algoritmen er trænet på nok data, vil den formentlig indsætte ord såsom forhøjet eller højt i denne sammenhæng. Dermed vil ordene højt og forhøjet få word embeddings der minder om hinanden, ligesom de semantisk også minder om hinanden i sætningen.
I dette projekt udvikler vi danske medicinske word embeddings på en database bestående af 300.000 elektroniske patientjournaler. De trænede word embeddings vil være til stor gavn for både nuværende og fremtidige projekter som arbejder med kunstig intelligens til automatisk udtræk af informationer fra patientjournaler. Fx vil dette muliggøre omsætningen af den ustrukturerede notattekst i patientjournaler til struktureret data – fx om et notat indikerer at patienten har et bestemt symptom.
For yderligere information kan du kontakte os på